
Разбор визуализации о рынке труда и оцифровке профессий
Пока это самый большой мой разбор. Написать его получилось только по частям, публикуя в телеграм-канале. Соавтор пересланного решения — Роман Бунин, без которого я провозился бы раз в 5 дольше, и не факт, что нашёл бы все удачные ходы.
Предмет разбора
Меня привлекла работа Стива Левина для Аксионс об оцифровке профессий, изменении зарплат и числа рабочих мест в США:
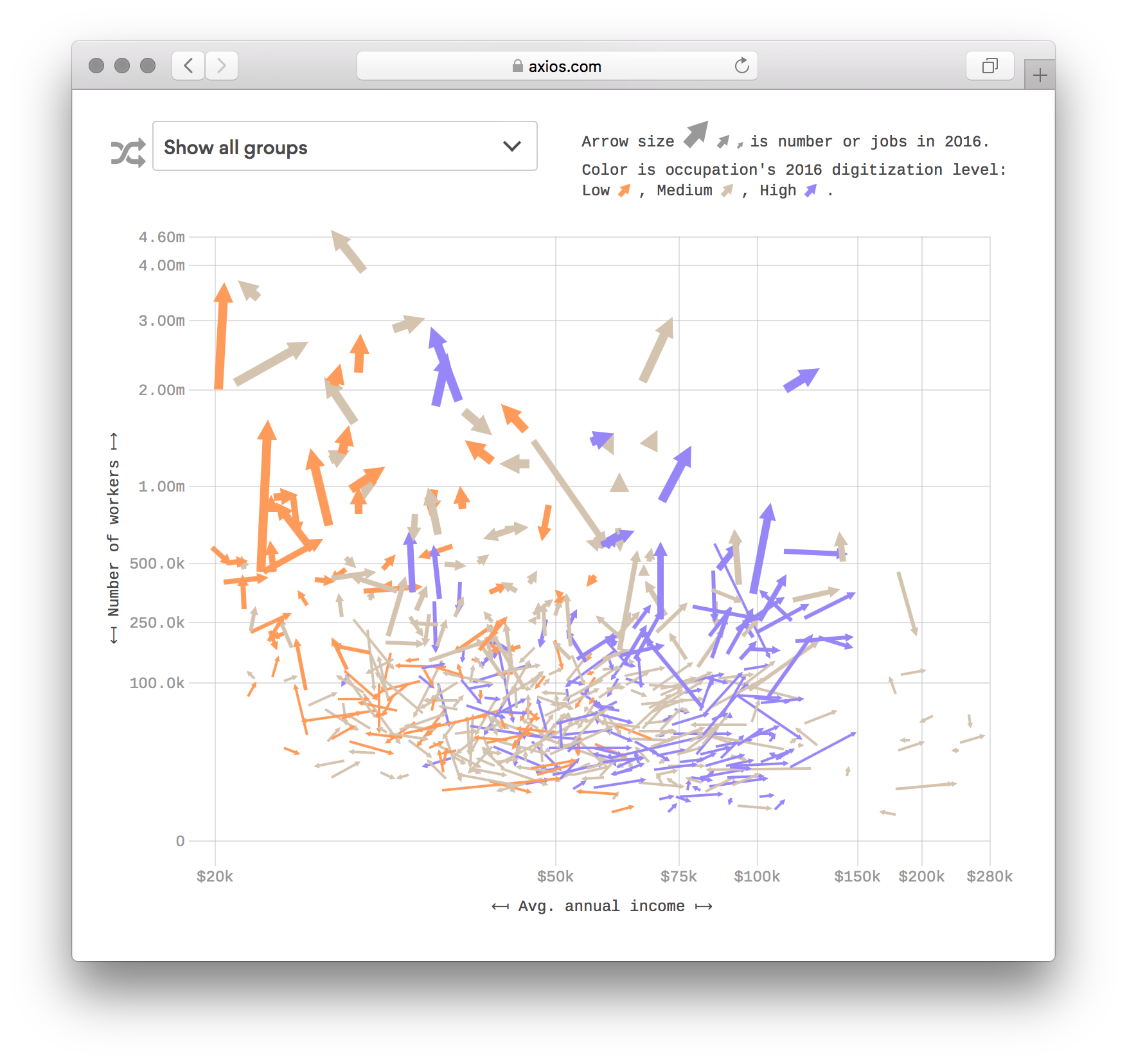
Привлекла внешней простотой, аккуратностью и тем, что в ней легко копаться. Закопавшись, понял, что она иллюстрирует только заголовок «People in highly digitized jobs earn more...» (Люди с высоко оцифрованный работой зарабатывают больше). Это видно из положения оранжевого и фиолетового облаков стрелок. Мне связь зарплаты с оцифровки очевидна, поэтому полез разбираться, что в визуализации ещё интересного.
Визуализация построена на данных исследования Брукингского института. Вместе с отчётом институт опубликовал визуализации. Можно посмотреть на те же данные под другим углом. Тут акцент на степень оцифровки, но совсем не показаны зарплаты:
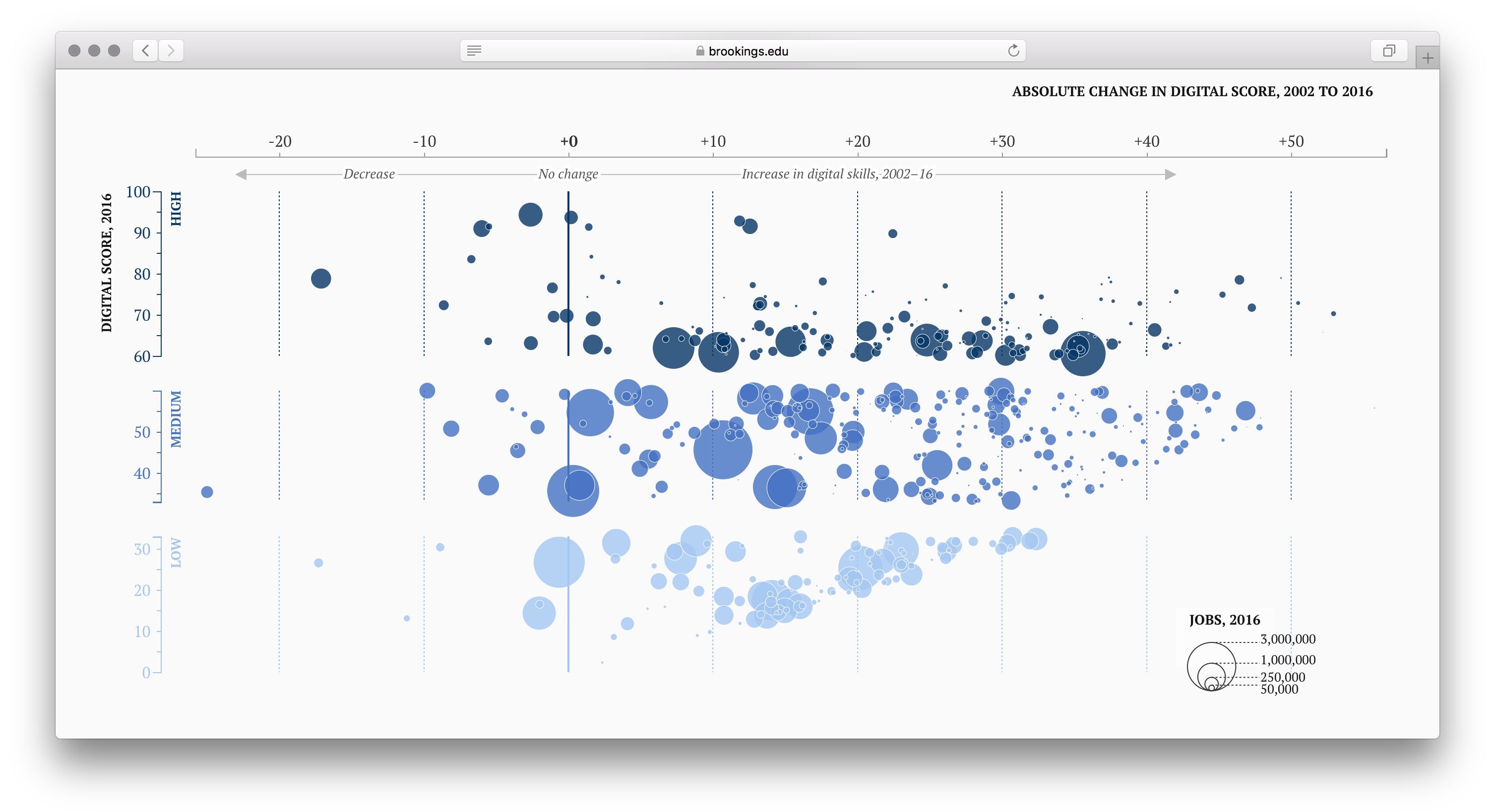
В формате разбора не успею закопаться в исследование и детали всех визуализаций. Ограничусь работой Стива, то есть срезами оцифровки, зарплат и числа рабочих мест за 2002 и 2016 года. А география, образование, цифровые навыки и прочее останется за скобками.
Устройство и ошибки
Сразу понять, в чём проблема, было сложно, поэтому формально описал устройство визуализации и перечислил ошибки, которые могу легко объяснить и решить.
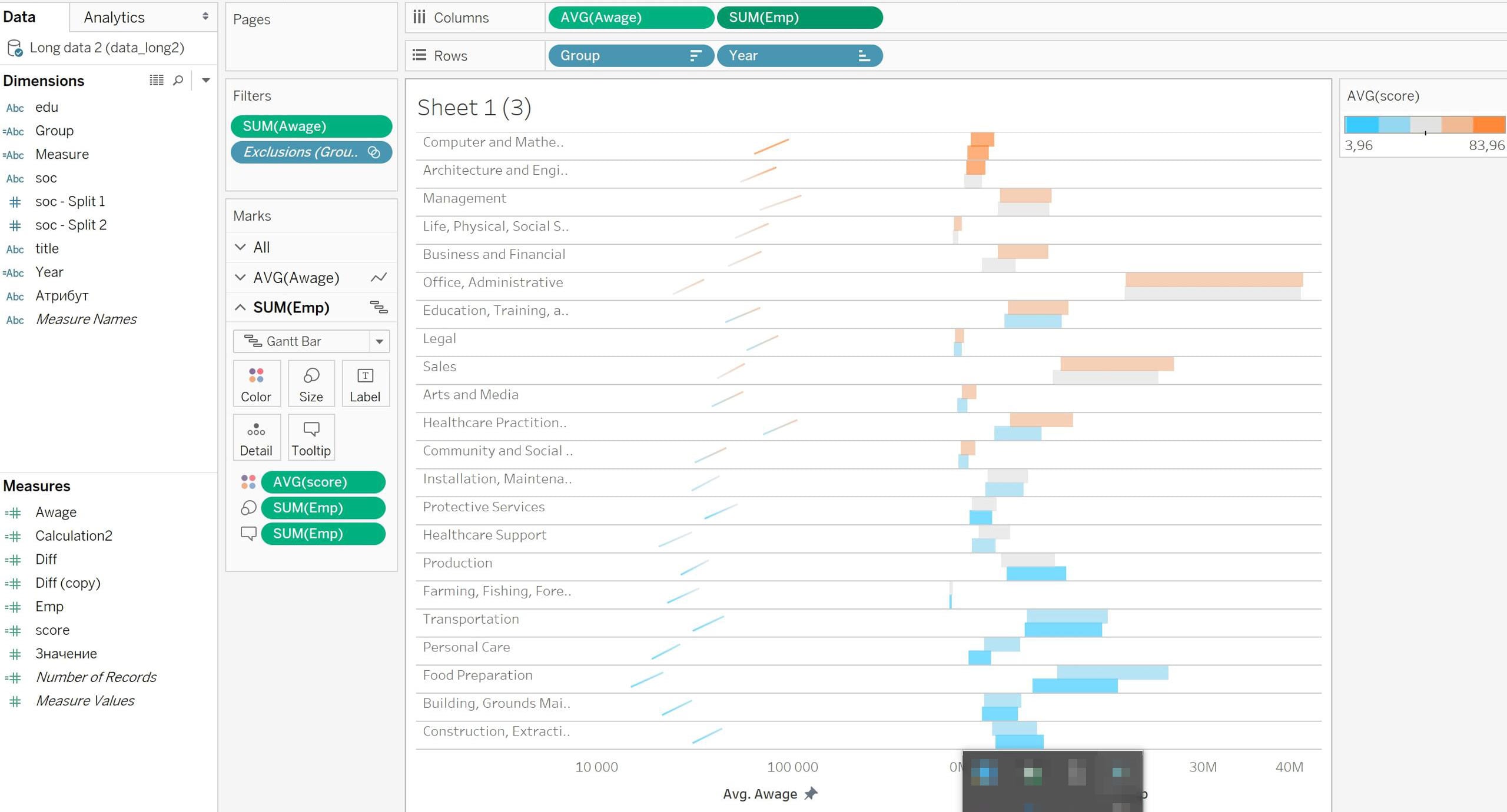
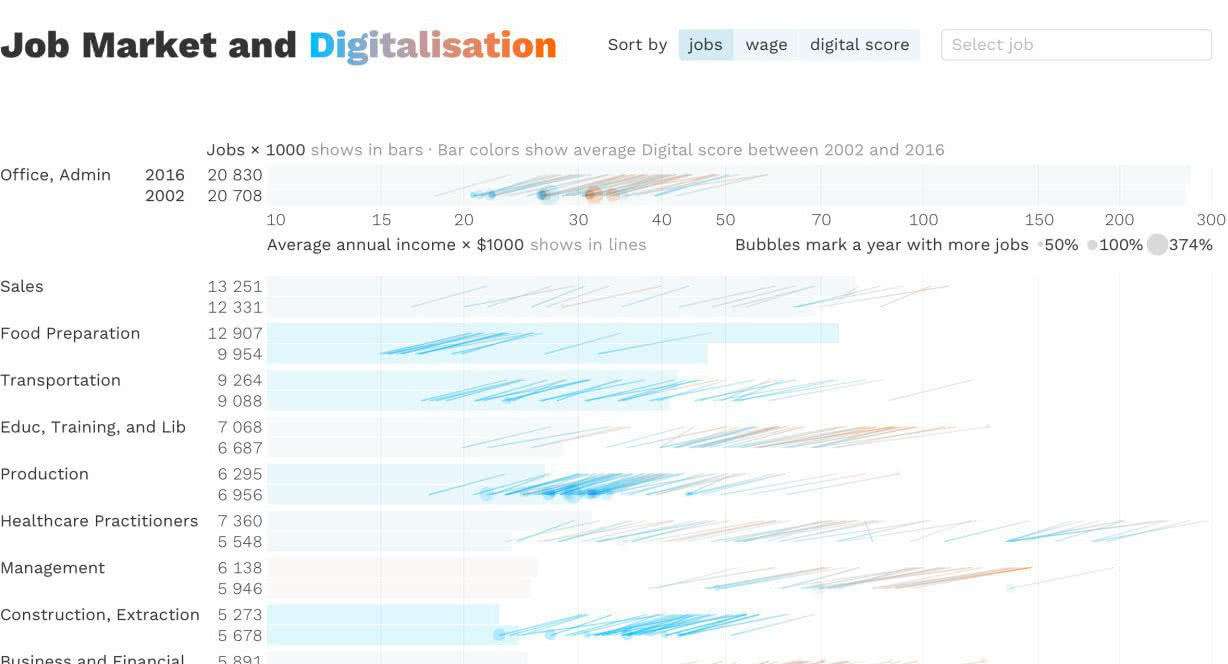
Сначала — каркас. Тут два измерения со степенными шкалами: икс — средняя годовая зарплата, и игрек — число рабочих мест. Каждая стрелка — профессия. Основание стрелки — зарплата и число мест в 2012-м, остриё — в 2016-м.
Толщина штриха (и размер острия) кодирует число рабочих мест в 2016-м. Число рабочих мест закодировано дважды — положением по игреку и толщиной штриха. Двойное кодирование — рабочее решение, но тут оно выглядит случайностью. Возможно, если толщина штриха будет меняться вслед за изменением числа рабочих месть, падение и рост будут нагляднее.
В таком каркасе может казаться, что видны изменения, а из-за стрелки — ещё и будущий вектор. Но на деле данные только за два года, что происходило между неизвестно, и тем более — что будет в будущем.
Из-за того, что толщина стрелок показывает число рабочих мест, индустрии с больши́м числом рабочих привлекают больше внимания. Не проблема, что визуализация это показывает — это реальность, хирургов меньше, чем фасовщиков. Но в таком представлении искажается восприятие — маленькие стрелки не замечаются, даже при большой зарплате. Спорное решение.
Цвет отвечает за оцифровку профессии на 2016-й, у него три дискретные шага: слабая оцифровка, средняя и сильная. Вижу две проблемы:
- Цвета не ассоциативные и неравномерные по насыщенности — бежевый выглядит менее заметным на фоне ярко-оранжевого, кажется, что тут низшая степень оцифровки. В своей версии возьму оранжевый для высоких значений и голубой для низких. Теплота цвета будет отвечать за «температуру» оцифровки.
- К дискретности тоже вопросы. Она бывает свойством данных из-за низкой точности оборудования, например. Но в отчёте, на который ссылается визуализация, виден разброс:
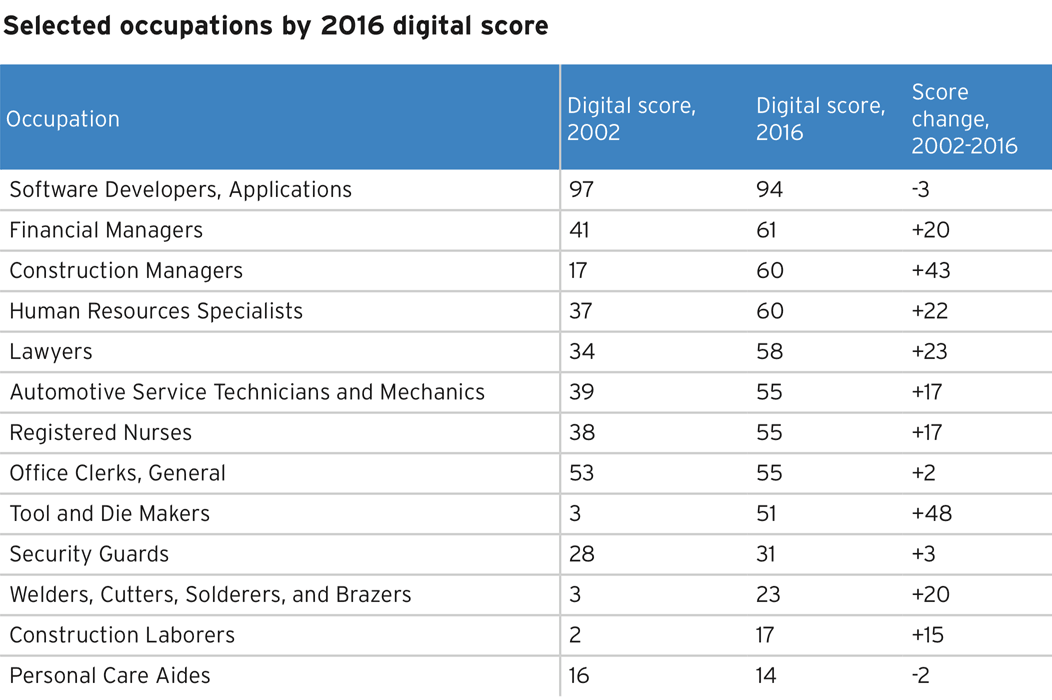
В таком случае лучше брать градиент с промежуточными значениями. А если красить вершины стрелки разными цветами, будет видно растёт оцифровка или падает.
Описывая недочёты, я думал, что их исправление улучшит визуализацию. Так сделаны некоторые прошлые разборы. Умозрительно понимал, что исправления не изменит общую картину, поэтому переделал полностью.
Cвой подход
Вспомнил работу Нью-Йорк Таймс о профессиях и соотношении полов на рынке труда среднего класса США в 1980 и 2012. C визуализацией данных тоже помогает насмотрелось, мозг сам вспоминает похожие форматы и структуры данных.
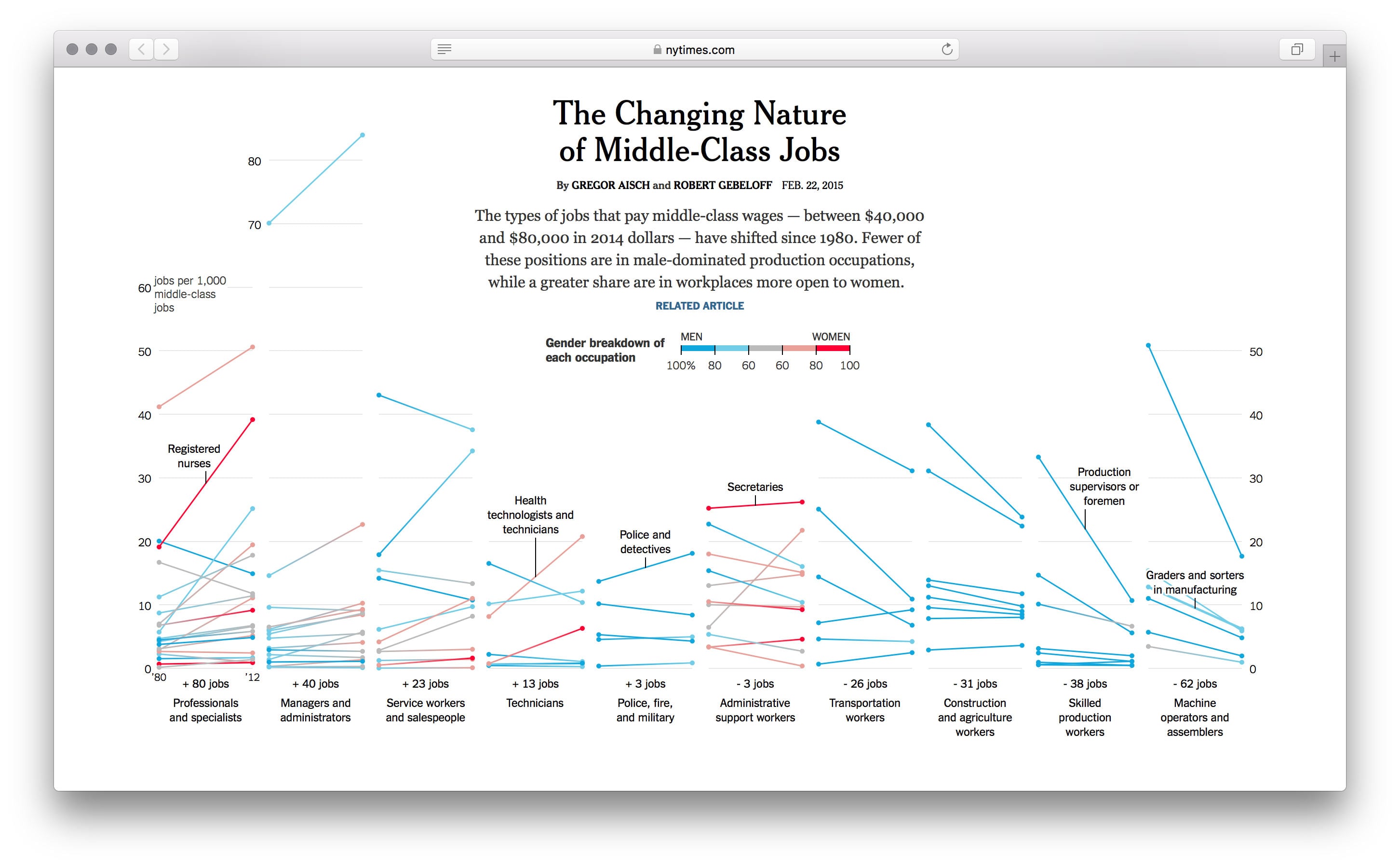
Иду за помощью к Роме, с которым работали в Лаборатории данных. Чтобы пробовать, нужны данные. Нашёл их на странице исследования на сайте Брукингского института:
Дальше устраиваем скайп-сессии и обсуждаем идеи вместе, примеряя в табло. Выделяем две основные гипотезы.
Гипотеза 1.0. Показывать зарплаты графиком наклонов (slope chart) — так называют графики из примера выше. Разбить профессии на группы по одной оси, чтобы упорядочить кашу.
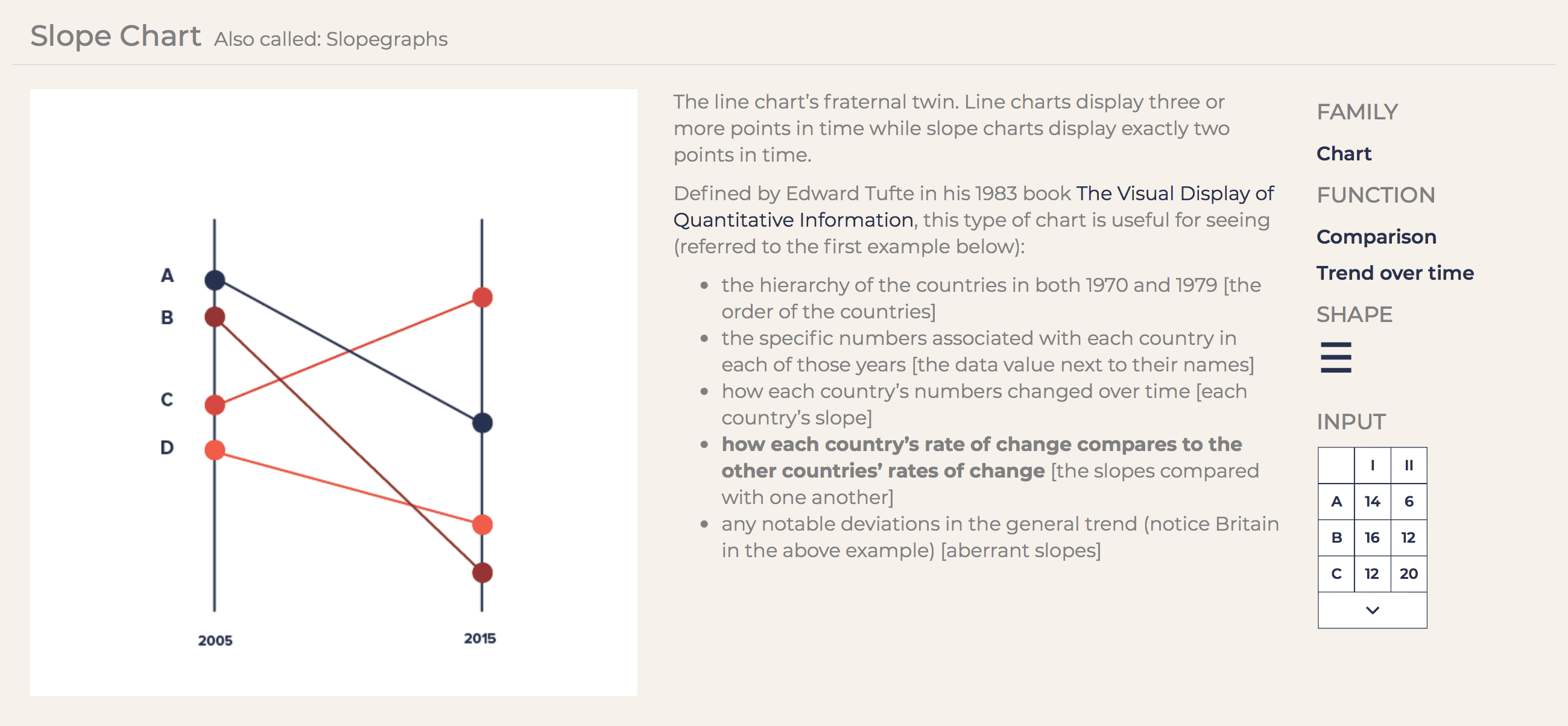
Гипотеза 2.0. Смотрю, какие ещё классифицированные графики работают с похожими «вводными» (блок «Input» справа). Показывать зарплаты горизонтальными гантелями (dumbbell plot).
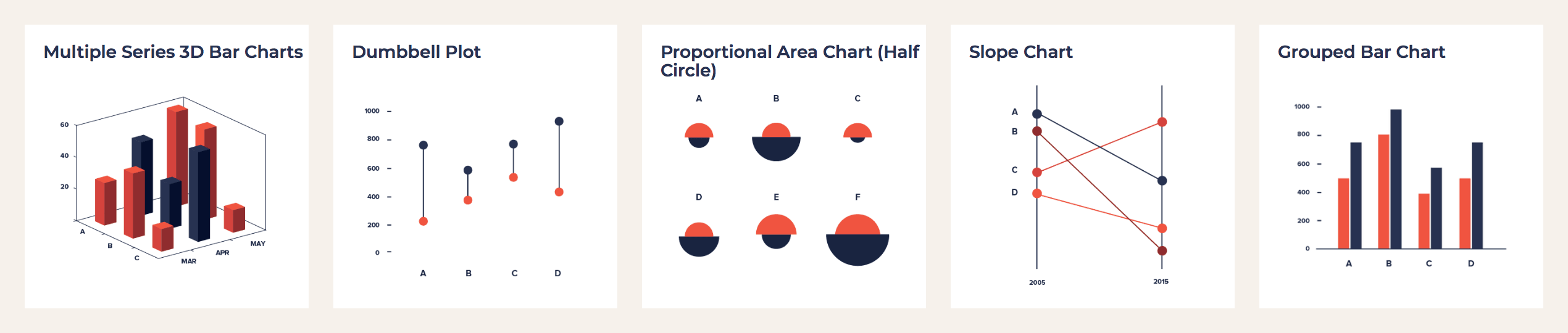
Гантели не работают. По иксу — зарплата. Вершины гантели — зарплаты за 2002 и 2016 года. Но понять, где какой год не получится, потому что зарплата могла как расти, так падать:
А графики наклонов выглядят перспективно. Тут 2002 всегда слева. Сразу видно, что реальное падение зарплат только у двух профессий — в колонках с номерами 29 и 27:
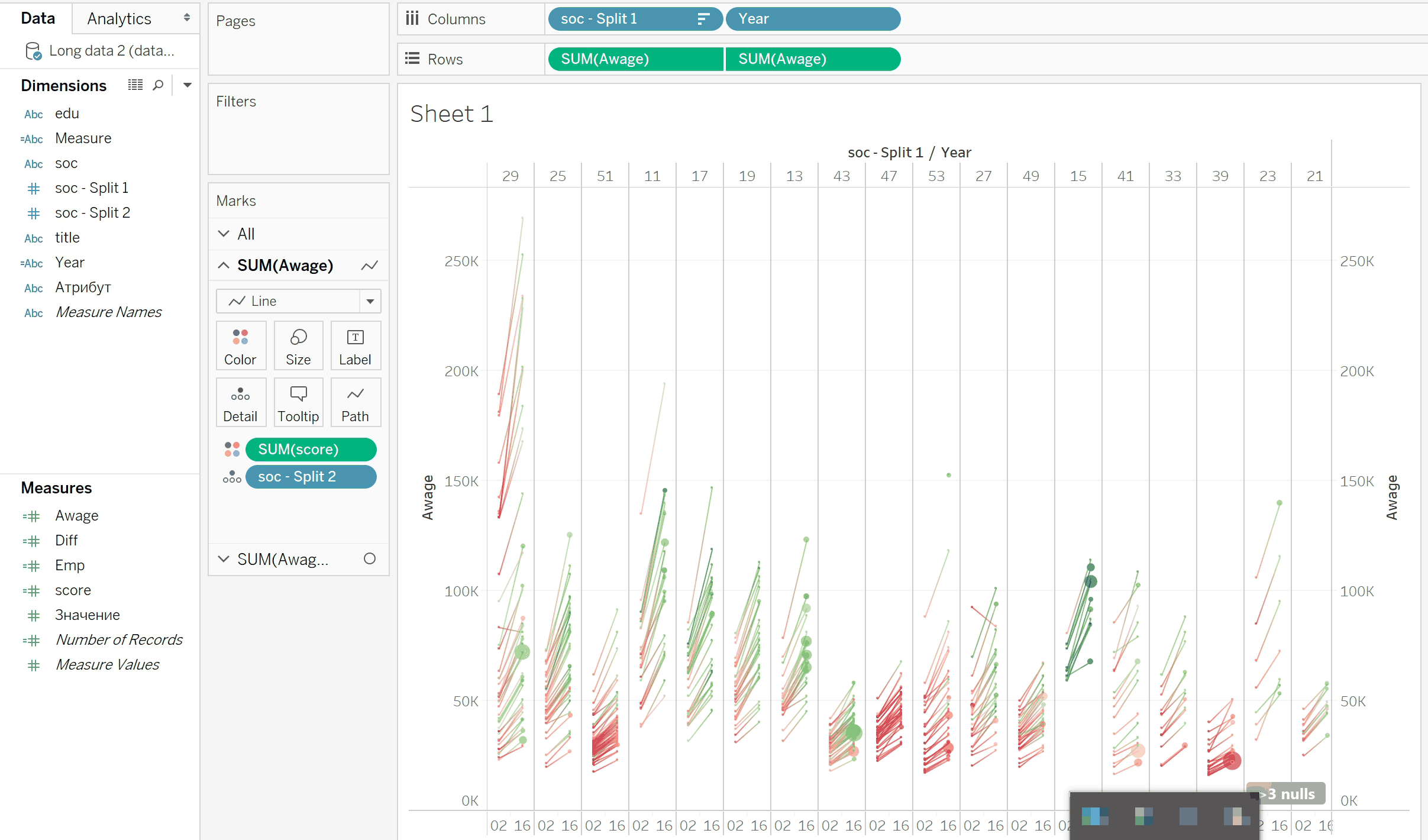
Проработка
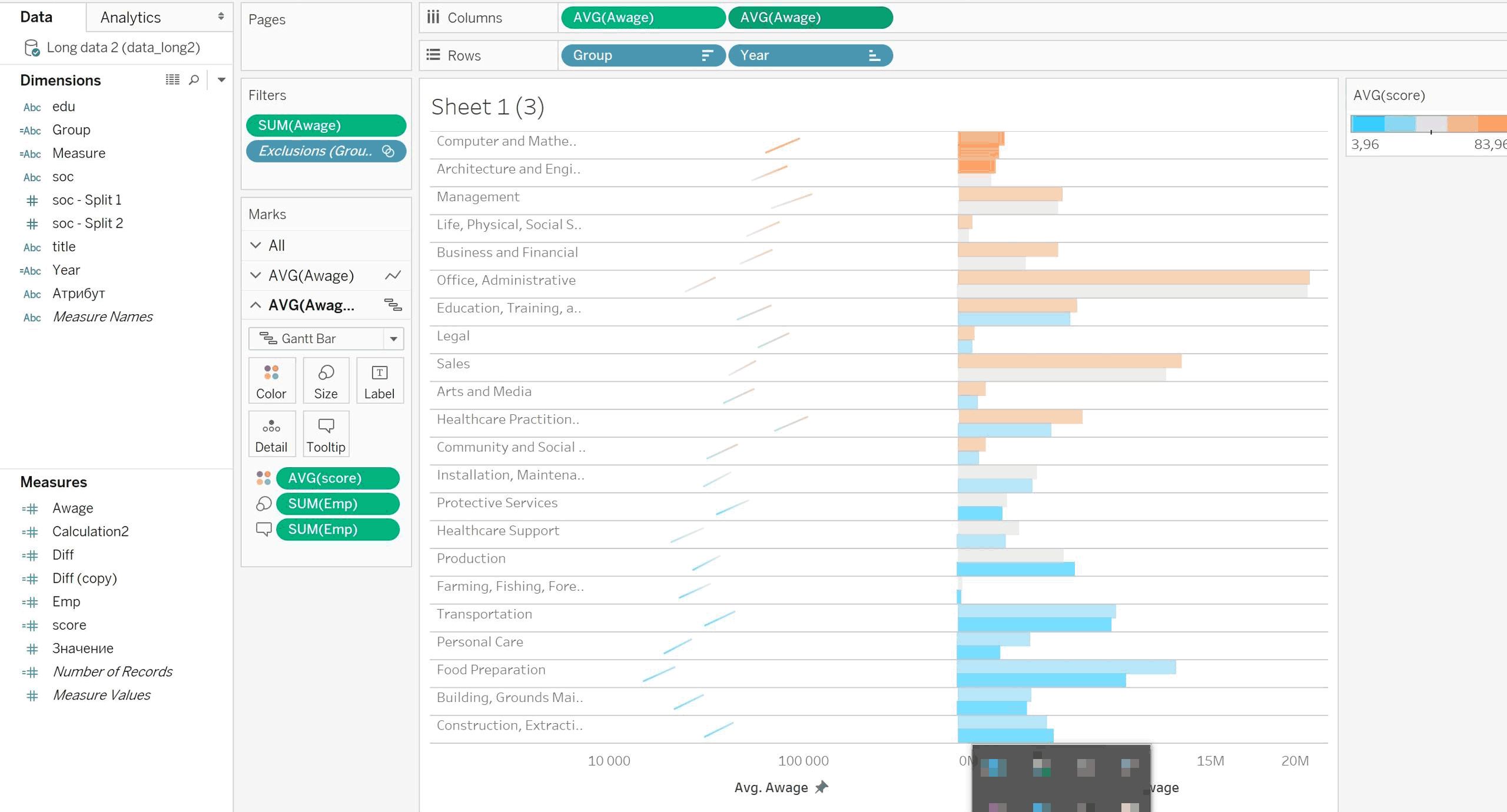
Пробуем для оцифровки градиент насыщенности, но с ним ничего не видно. Поэтому вернёмся к комплементарным цветам.
Оказалось, что в данных группы профессий заданы только цифрами (они и видны в колонках сверху). Нахожу соответствие на сайте Аксионс. Переворачиваем всё на 90°, чтобы нормально читать названия групп. Экспериментируем с цветом.
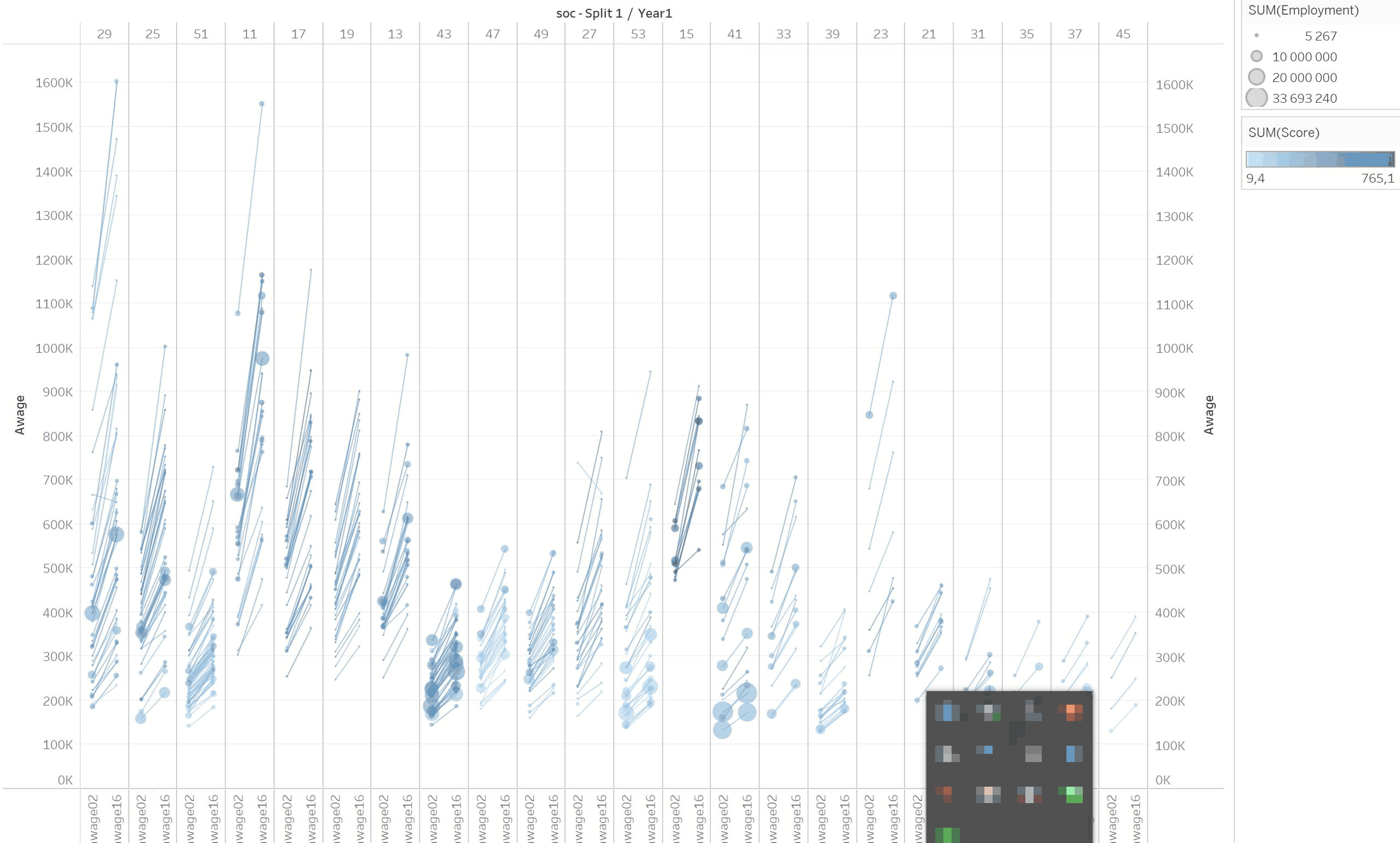
По иксу — зарплаты, шкала — равномерная. На такой шкале удобно смотреть, насколько быстрее растут ставки высокооплачиваемых специалистов.
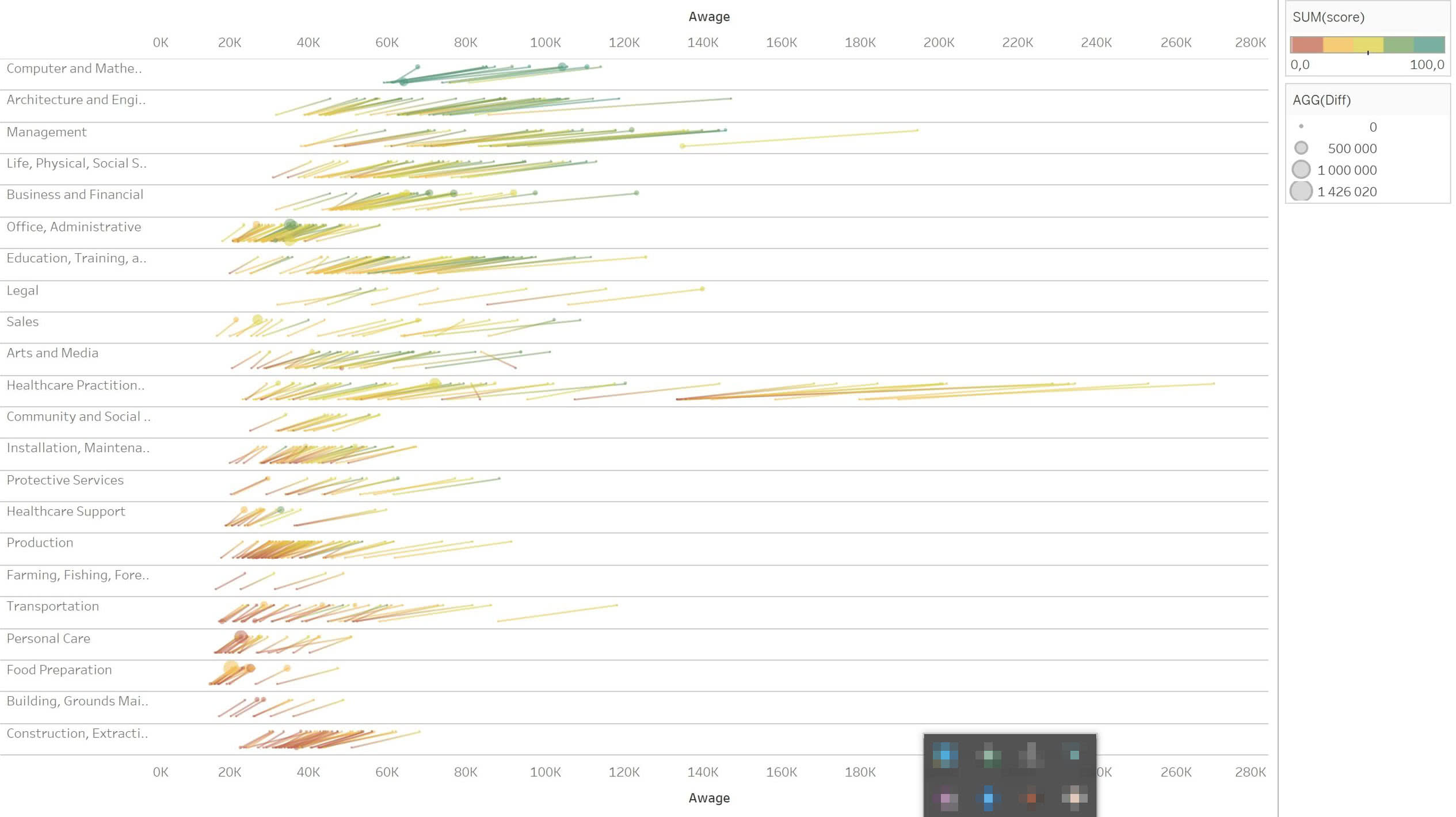
А чтобы сравнивать рост ставок удобнее смотреть с логарифмической шкалой. Она показывает процентные изменения:
Логарифмическая шкала нагляднее показыват, что относительно самих себя зарплаты растут более-менее одинаково. Например, одним платят 1000 $, а другим — 5000 $. С инфляцией в США с 2002 по 2016 происходит вот что:
Чтобы труд не дешевел и не дорожал из-за инфляции, зарплаты должны меняться вслед за инфляцией. В 2002-м зарплат в 1000 должна превратиться в 1023,8 (1000×(100+2,38)/100), в 2003-м 1023,8 — в 1043. И так до 1366,4 $ в 2016-м. А зарплата в 5000 за это время превратится в 6832,1 $. В долях это одно и то же, а в долларах 366,4 $ против 1832,1 $.
С логшкалой видно, что зарплаты реагируют на изменения в экономике более-менее одинаково — углы наклонов полосок почти одинаковы. А те случаи, где они отличаются, справедливо привлекают внимание — это профессии, к которым «действительно» стали платить больше или меньше.
Ещё плюс логарифмической шкалы для этой визуализации — данные занимают меньше места по горизонтали.
Подробнее о шкалах читайте у Ромы.
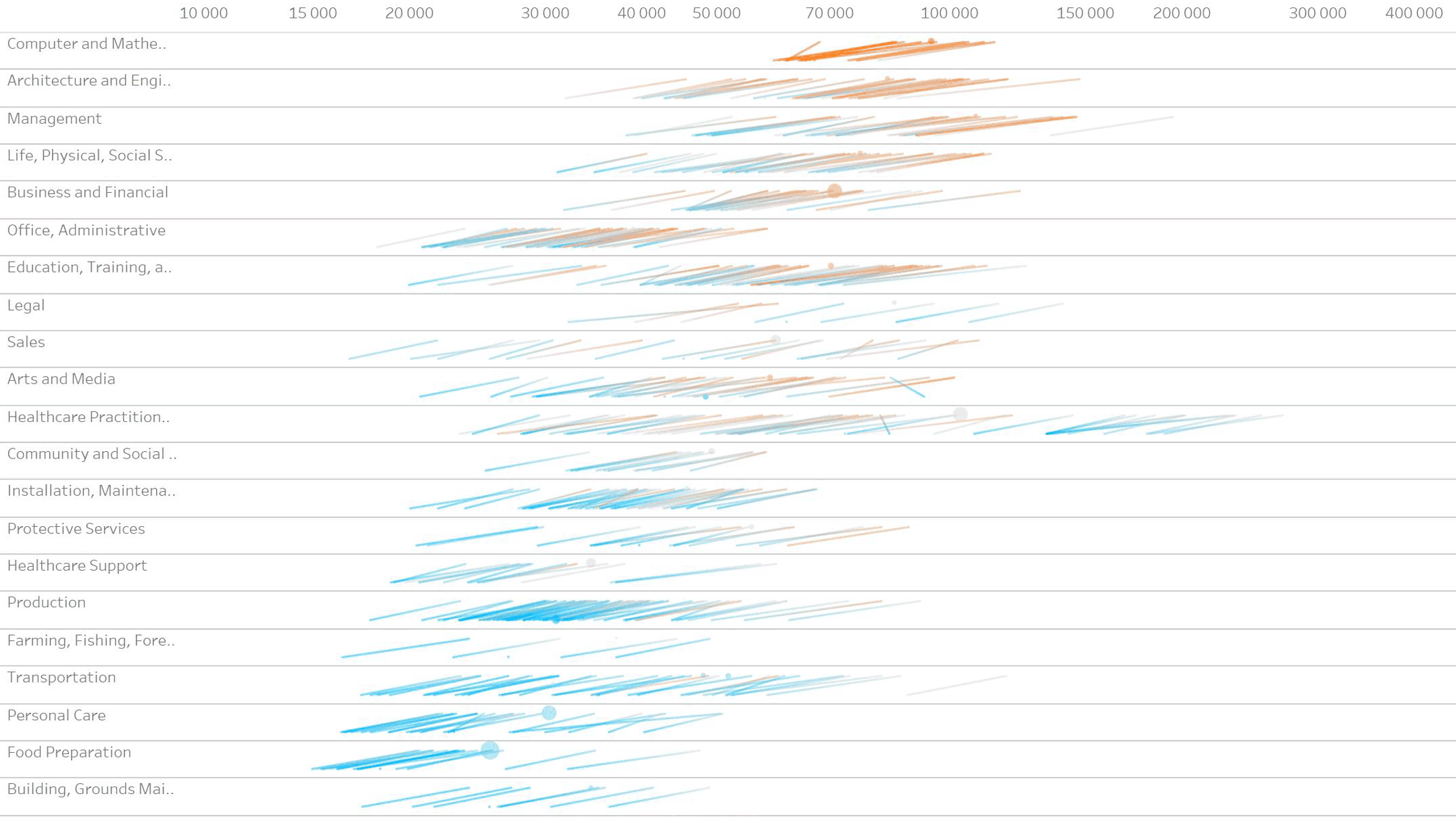
Гипотеза 1.1.0. Агрегировать зарплаты по группам. Идея плохая — теряется куча данных и сглаживаются все аномалии:
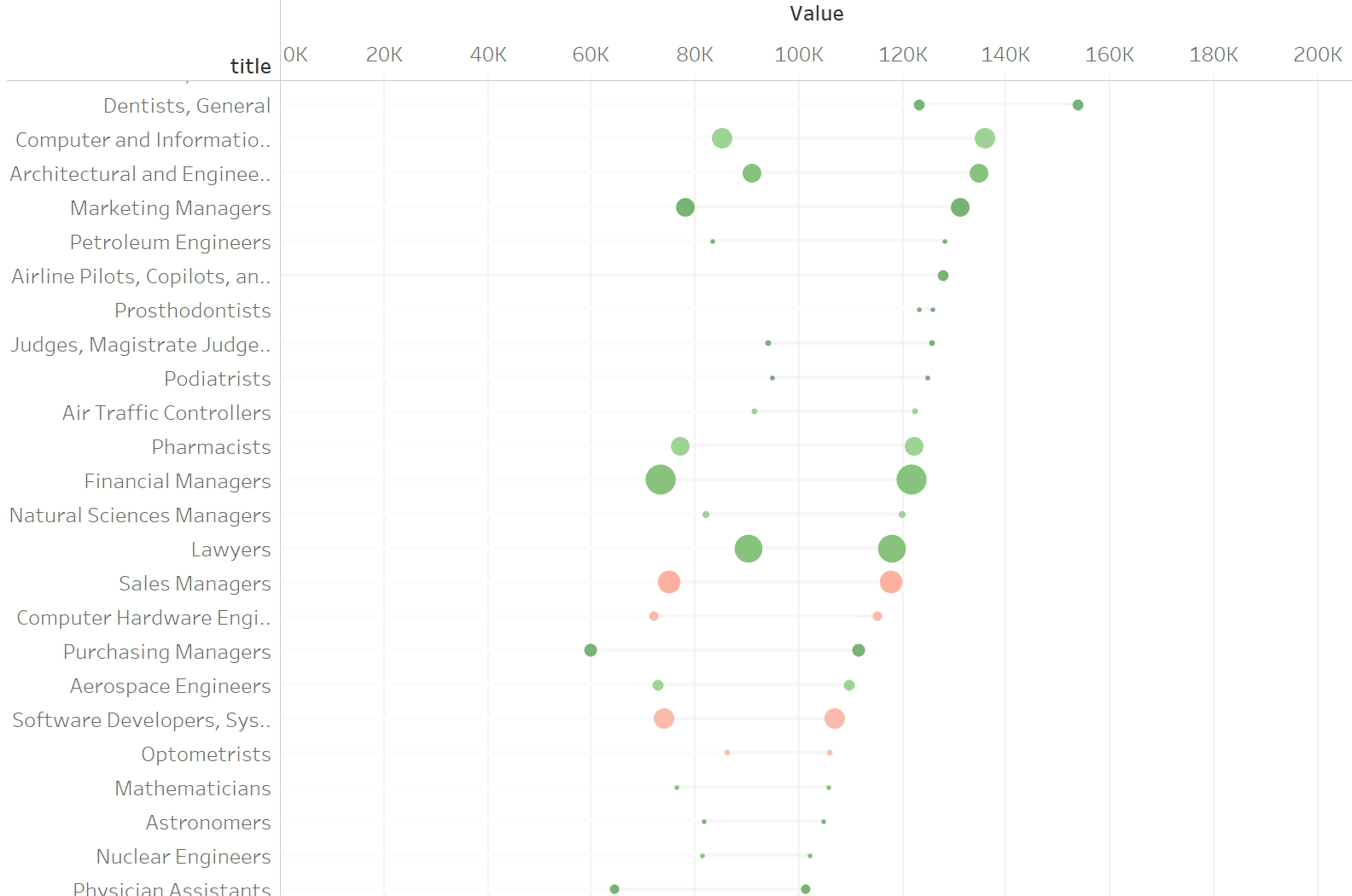
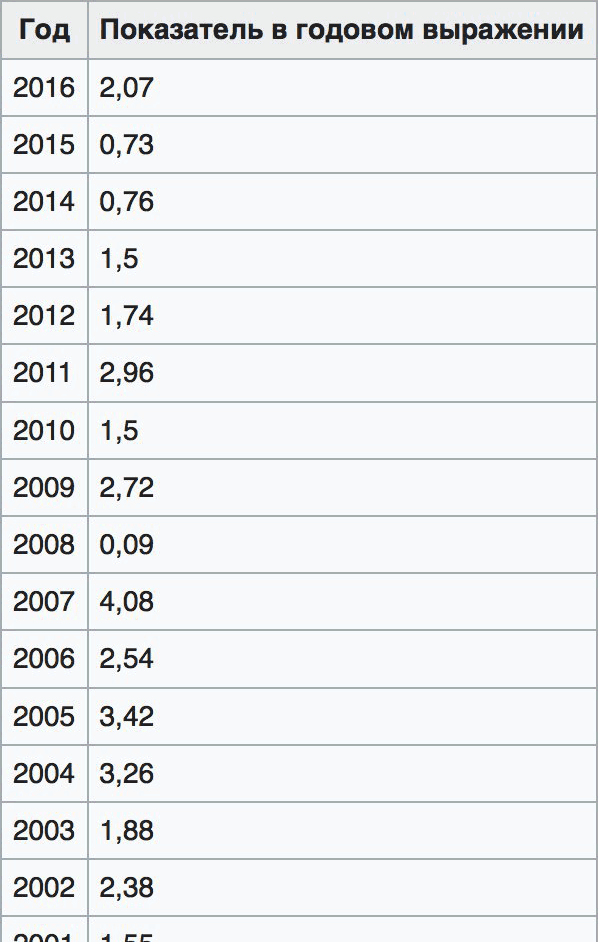
Гипотеза 1.2.0. Показывать количество рабочих мест кругами на концах линий. Сначала смотрим на уровне групп. Картина непоказательная:
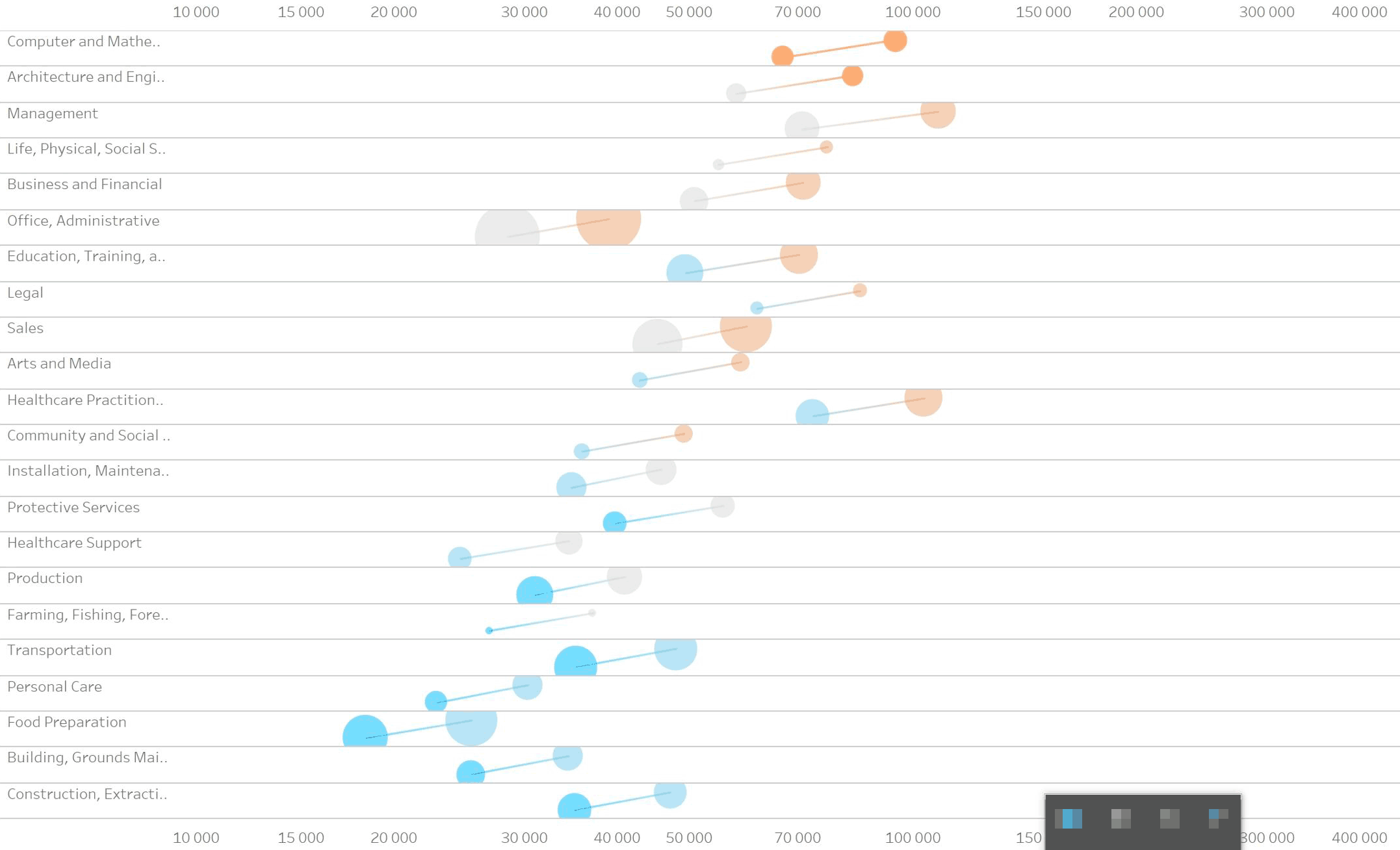
Гипотеза 1.2.1. Показывать только разницу и оставлять один кружок на том конце линии, который отвечает за год с больши́м числом рабочих мест. Опять не наглядно:
Гипотеза 1.2.2. Может, вместо кружков горизонтальные столбики?

В Табло так не получится. Откладываем идею, но смотрим, что вообще выходит из столбиков. Направление кажется перспективным.
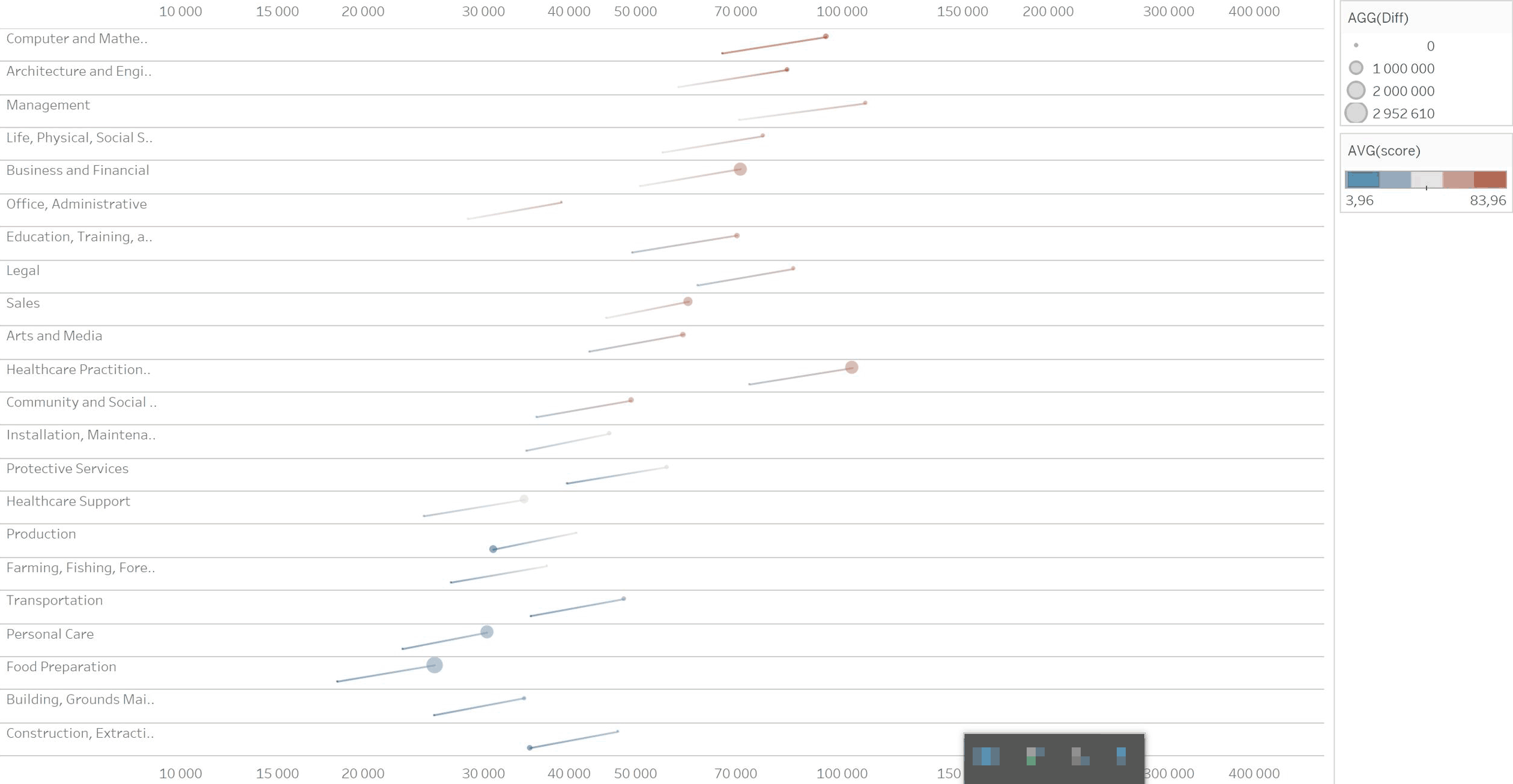
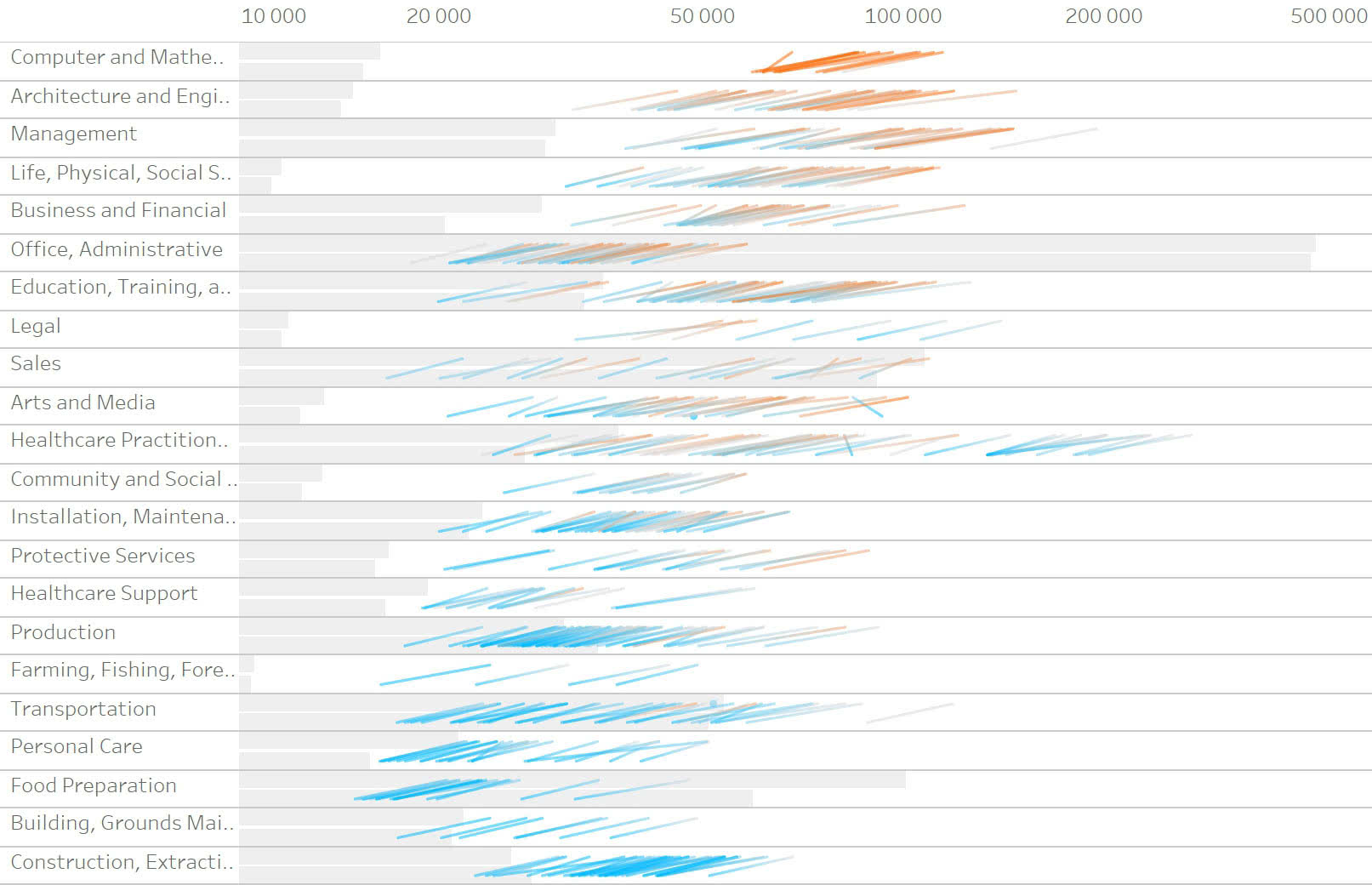
Совмещаем их с заголовками и пробуем красить в зависимости от степени оцифровки. Разноцветные столбики плохо группируются в пары:

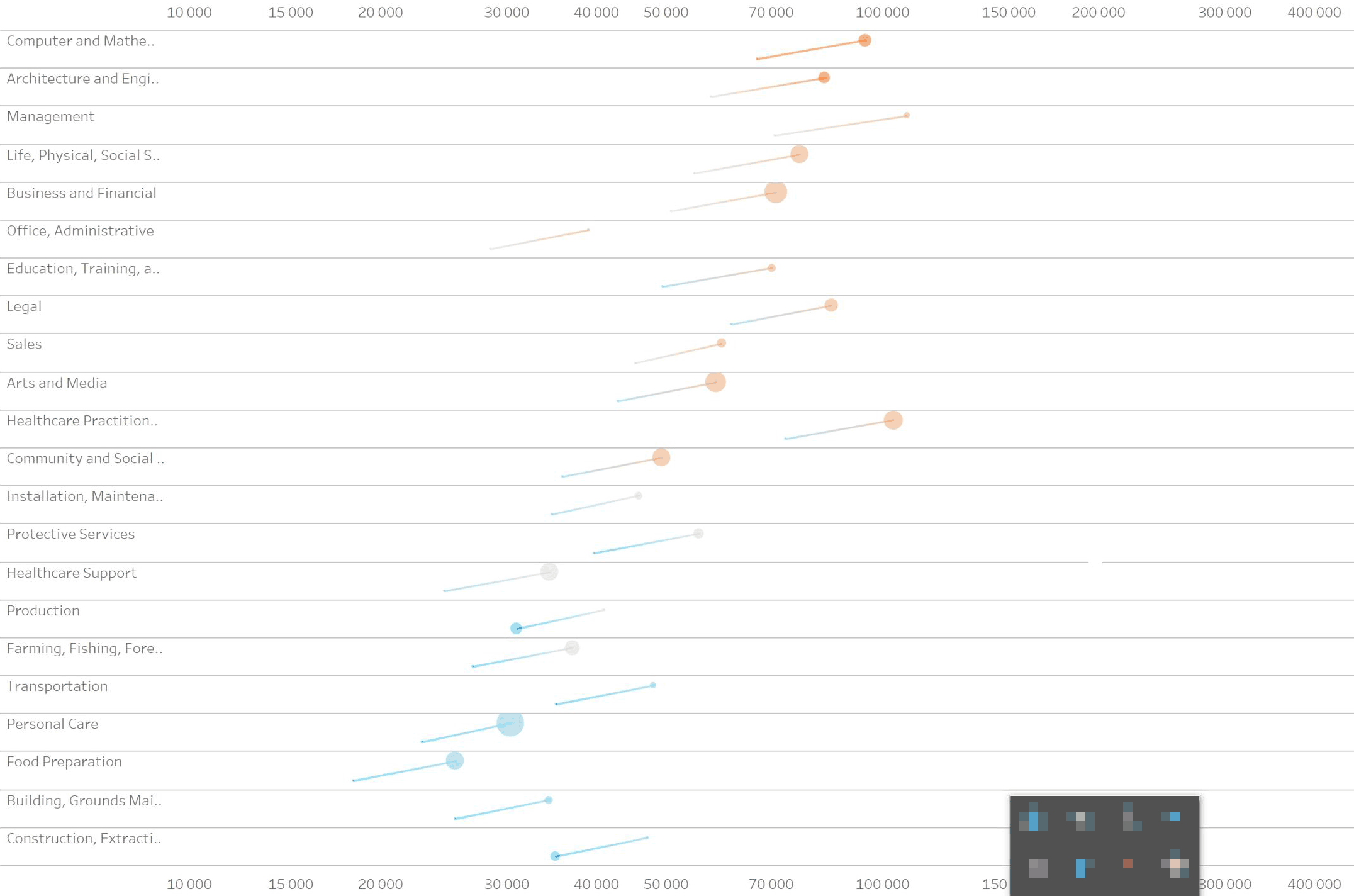
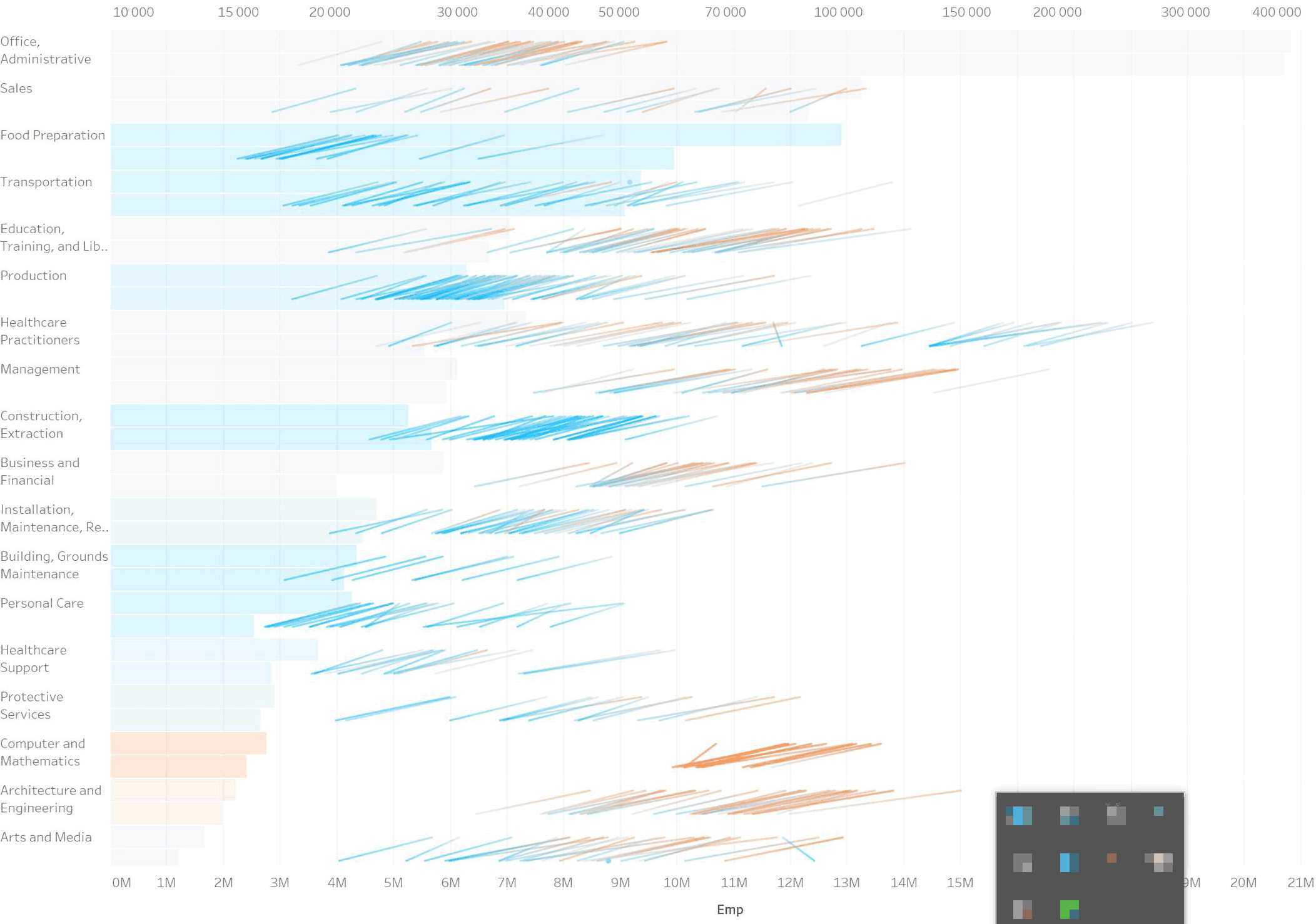
Убираем цвет. Сортируем по количеству рабочих мест:
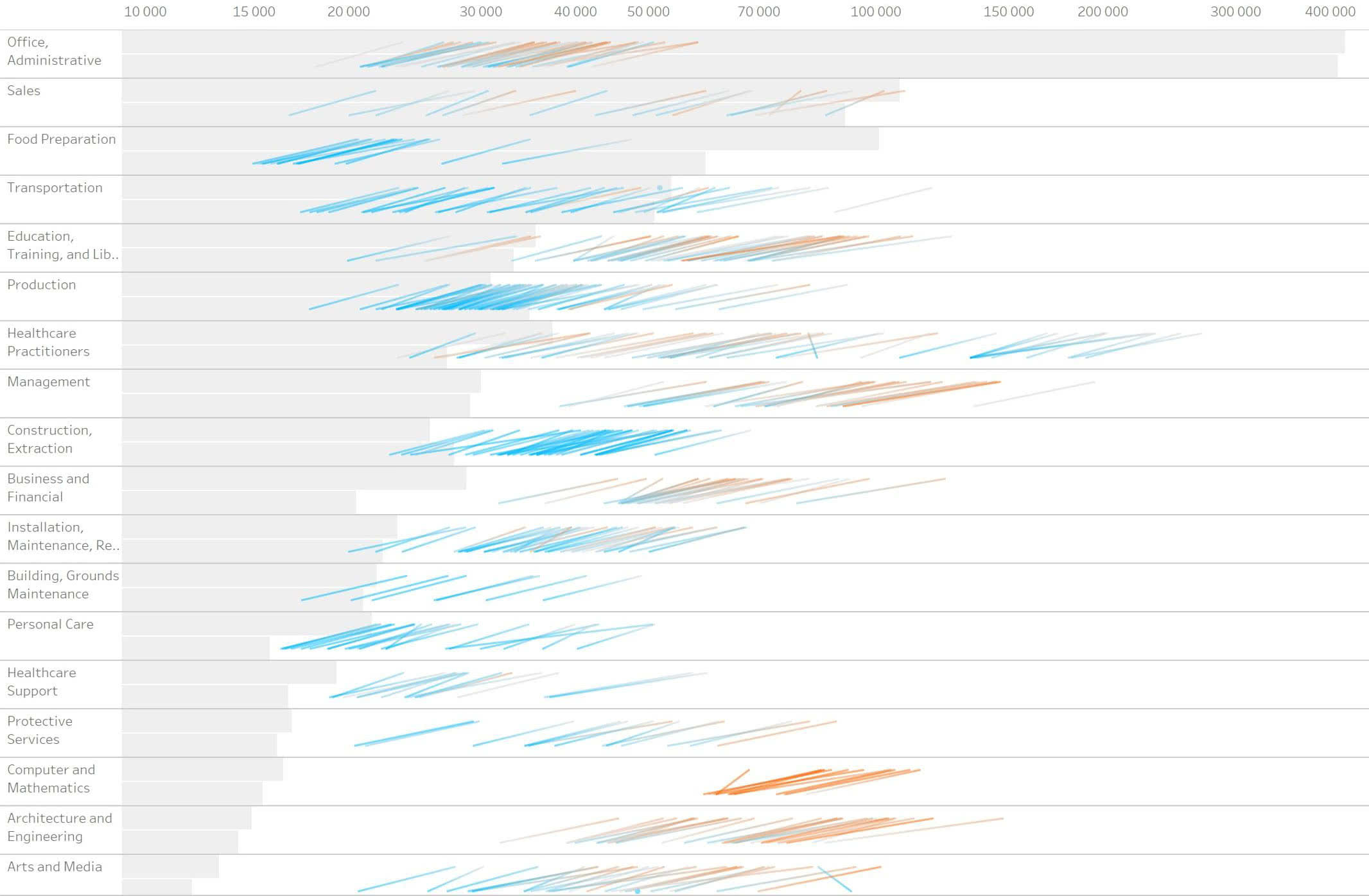
Теперь столбики сливаются в одну массу. Придумываем красить их попарно цветом, который соответствует среднему между оцифровкой 2002-го и 2016-го. Это нечестные данные, потому что в промежуточные года данные были другими. Такие средние в целом не корректно считать, их нет в природе. Но тут оно помогает показать пары. К тому же у нас и так столбики — агрегация до групп, что тоже не очень корректно. В целом столбики показывают как дела на макроуровне, поэтому оставляем. Добавляем точные значения и подкручиваем цвета:
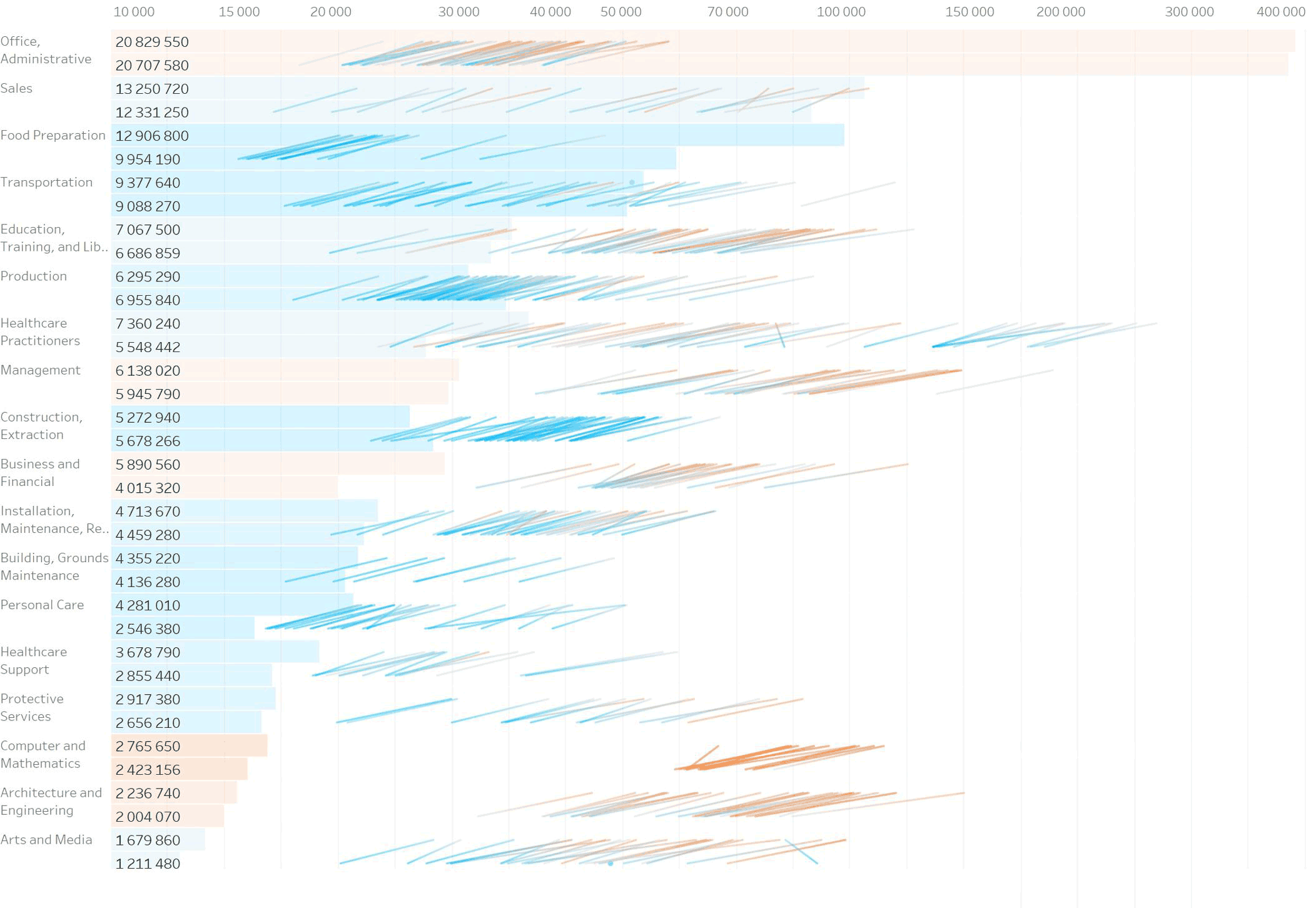
Чистовая вёрстка
Объясняю как устроена строка на примере первой группы. Рисую переключатель сортировки и поиск, который на деле был бы выпадающим списком с фильтром по введённым буквам:
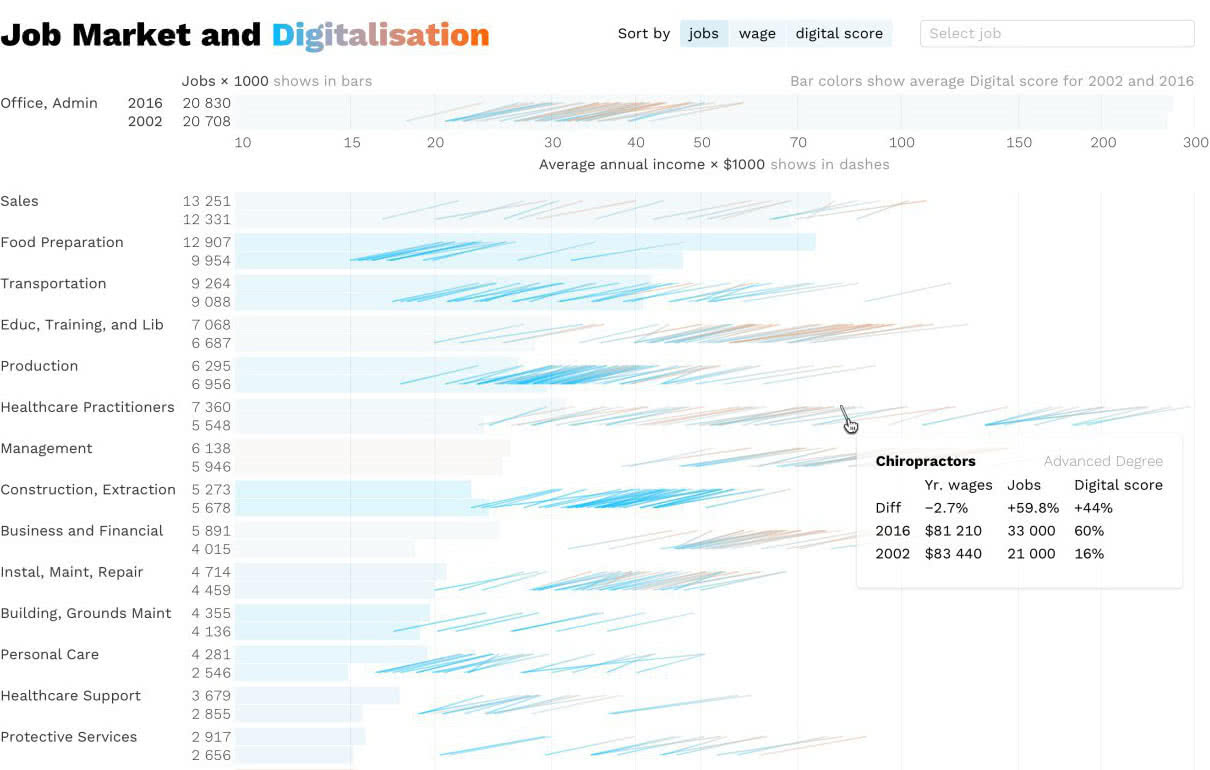
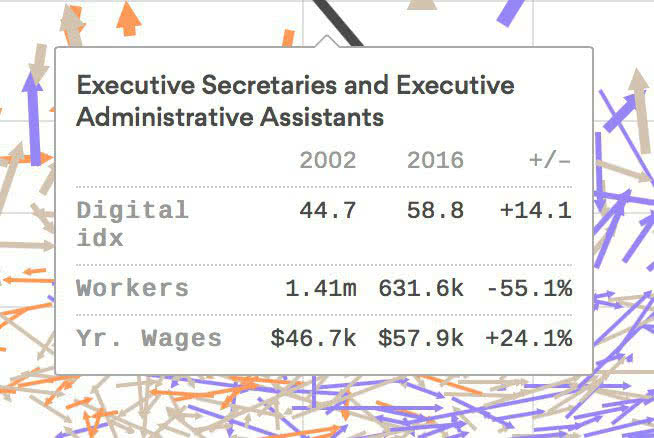
Переворачиваю таблицу в подсказке, которую видно при наведении на линию. В оригинале значения для разных лет стоят в строке, а сравнивать цифры удобнее в столбиках:
Гипотеза 1.2.1.1. Возвращаемся к идее показывать на одном из концов линии кружок, который покажет разницу в числе рабочих мест и год, когда было больше. Добавляю кружки и легенду к ним. Кружки выглядят неубедительно, а легенду сложно читать.
Снова разбираемся с данными. Оказалось, что неправильно посчитали разницу. А спустя 2-3 попытки понимаем, что показывать разницу в процентах — плохая идея. Проценты считаются от исходного значения. Было 1000 мест, стало — 1100, это +10%. Если было 1100, а стало — 1000, это −9,1%. Количество мест одинаковое, а процентное изменение разное. Сравнивать такое некорректно. Вместо процентов, берём разы. Исхожу из того, что интересуют профессии, в которых были значительные изменения, поэтому предлагаю показывать кружок, только если изменение больше, чем в 1,5 раза.
Финальный макет, к которому мы пришли через последовательные ответы на четыре основных вопроса и проверкой минимум по два варианта для каждого вопроса.
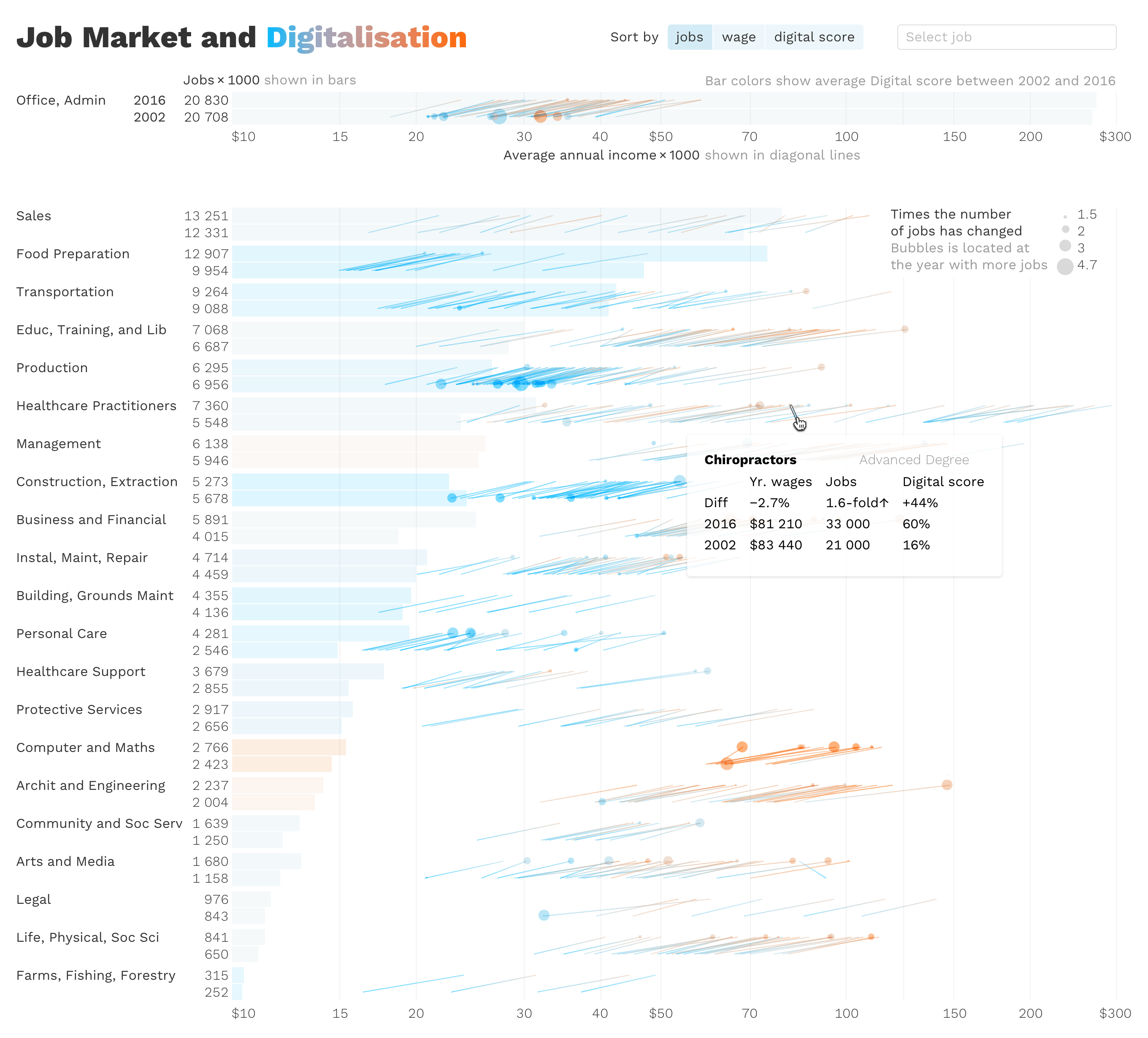
Рома выложил прототип в Табло. Помимо описанного, там есть разбивка по образованию:
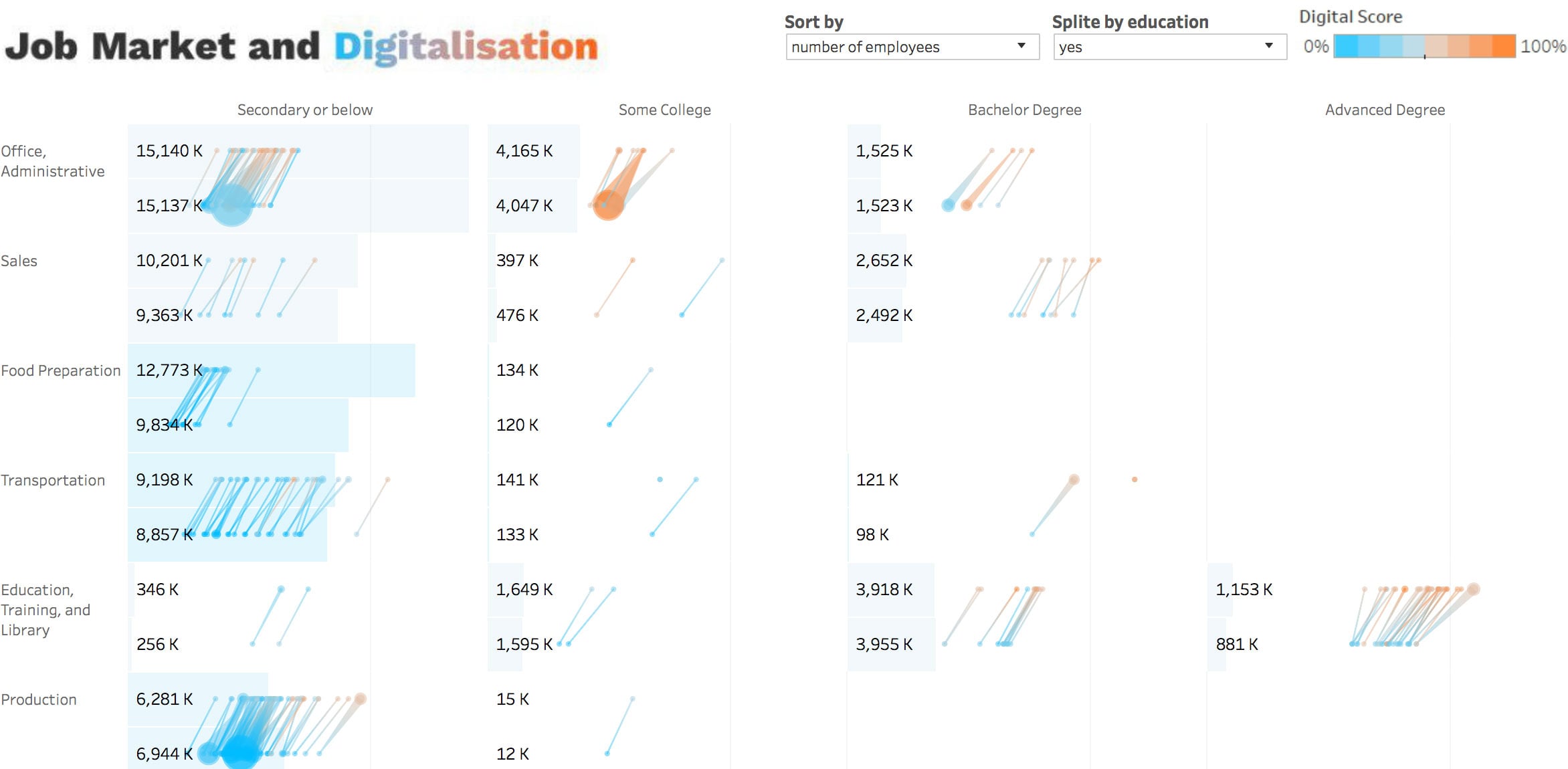
«прототип в Табло» — ссылка нуждается в протоколе, что бы перейти на правильный сайт